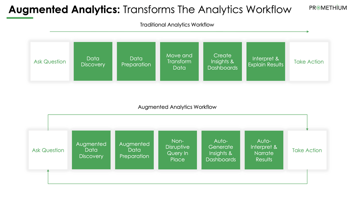
Augmented analytics involves using machine learning and natural language processing (NLP) to assist...

Gartner projects that manual data management tasks will be reduced by 45 percent in the next three years. How? Through Augmented Data Analytics (ADM), the twin of augmented data analytics that Gartner included in its recent list of top 10 data and analytics and tech trends for 2019.
💡 See what makes Augmented Data Management possible.
This new category promises to not only free data engineers, architects and scientists from rote tasks, but also pave the way for the “Citizen Data Scientist” by making an organization’s data much more accessible to non-technical business experts.
Data management, of course, includes activities ranging from database admin to disaster recovery. When done right, it should protect you from the “garbage in” portion of “garbage in, garbage out.” But presently, this labor-intensive work deters highly paid professionals from doing what they’re trained to do. Only 20 percent of their time is spent on what you’re paying them to do--analyze data! Furthermore, all this complexity places data analysis far beyond the reach of business experts.
Augmented data management, however, promises to change things by adding Artificial Intelligence (AI) capabilities, Machine Learning (ML) and automation to standard data management practices to eliminate the manual stuff and expedite data-derived decisions. Additionally, it promises to add a layer of context and meaning to data that makes it actionable for the non-technical.
Beyond automation of rote tasks
While augmented data management involves automating many routine tasks, we should be clear that these tasks aren’t trivial, nor are they jobs that don’t require quite a bit of expertise. For example, many of the ADM functions laid out by Forrester analysts Michele Goetz, such as labeling, classification, and tagging, require subject matter expertise as well as the understanding of how to operate within a database. The same can be said for gauging the value, completeness and trustworthiness of data, and determining whether it’s in compliance with company and regulatory policies.
However, such computationally intensive tasks do require massive repetition. When they’re automated through machine learning, they can be performed at scale, enabling insights to be derived from an organization’s data at an equally impressive scale.
Augmented data management, as Doug Henschen recently pointed out to TechTarget, combines automation with recommendation. For example, a simple natural language query on Promethium will yield a SQL query that joins automatically recommended tables to provide the requested data. However, it also allows the user to select between similar tables before finalizing the join.
Similarly, the auto-generated query can be further refined by the user to provide even more specific insights. In this way, it ‘augments’ the knowledge and skill that the experts--including both business and data mavens--are already bringing to the table. Human experts fully apply their acumen to make decisions, but they’re making much more informed decisions based on more complex data. Plus, they’re able to do it much faster thanks to dramatic improvements in a few key areas. A new standard for data quality To prevent the dreaded ‘garbage in/out’ scenario, data teams often must dramatically transform raw data before it’s production-ready. Augmented data management can automate many related processes, employing outlier detection to prevent abnormalities that might skew results, imputation of missing values, error detection and other techniques to provide a much more complete picture and make data usable. Ending alternate versions of the truth MDM aims to create the holy grail of data: a “single version of the truth”. In today’s enterprise landscape of data silos and hundreds of different platforms and tools, machine learning can employ algorithms to match and merge records and determine authority. While in the past some aspects of this may have been automated by hard-coded rules, ML algorithms apply more flexibility and context to the process, making more accurate suggestions during data mapping that mirror the decisions a human expert would make--but at infinitely greater scale.
Describing the data that describes the data The goal of metadata management is to make it easier to locate a specific data asset. Metadata, or data which describes other data, is also critical in understanding data lineage--or where the data came from and what’s been done to it since then. Make no mistake, when humans manage this, it’s a mess--metadata becomes inconsistent and incomplete. Imagine trying to find an obscure book in a public library without any indexing--that’s what the hunt for specific enterprise data is like!
Let’s face it, most of us aren’t librarians, and the process of documenting data is very tedious and time-consuming. But through ADM these processes can be automated so that data becomes easily locatable and lineage becomes traceable. It can even go a step further to infer metadata based on user behavior. In a very real sense, applying AI and ML to metadata management makes all the other cool aspects of ADM possible. In particular, it can make it possible to give users a clear picture of both the information contained within the data and the purpose that it serves within the organization, making what otherwise might be unintelligible to SQL developers accessible to non-technical audiences.
This is of course only the beginning of what ADM can accomplish. Soon we’ll see it informing all aspects of enterprise data architecture and management--from storage to analysis--and possibly even the performance of the databases themselves.
Stay tuned, things are about to get a lot more exciting!

